JavaScript 是一项令人印象深刻的技术。不是因为它设计得特别好,也不是因为世界上几乎所有可以访问互联网的设备都执行 JavaScript 程序。相反,JavaScript 令人印象深刻,是因为它的几乎每一个特性都使它成为优化的噩梦,但是它速度很快。
javascript 为什么会执行速度很快呢?这就是我们需要去深入探究的问题。
在本文中,我们将仔细研究不同 JavaScript 引擎用于实现良好运行时性能的一些技术,在研究过程中省略了一些细节,并简化了事情。本文的目标不是让您了解事物的确切运作方式,而是让您了解并理解引擎如何提升其运行时的一些基本知识。
执行模型
当您的浏览器下载 JavaScript 时,其首要任务是让它尽快运行。它通过将代码转换为字节码、虚拟机指令,然后将其移交给理解如何执行它们的解释器或虚拟机来实现。
您可能会问为什么浏览器会将 JavaScript 转换为虚拟机指令而不是实际的机器指令?这是个好问题。事实上,直到最近,V8(Chrome 的 JavaScript 引擎)还一直在做直接转换为机器指令的工作。
特定编程语言的虚拟机通常是更容易编译的目标,因为它与源语言的关系更密切。实际的机器有一个更通用的指令集,因此需要更多的工作来翻译编程语言以很好地处理这些指令。这种困难意味着编译需要更长的时间,同时也意味着 JavaScript 开始执行需要更长的时间。
例如,理解 JavaScript 的虚拟机也可能理解 JavaScript 对象。因此,执行像 object.x 这样的语句所需的虚拟指令可能是一两条指令。一台不了解 JavaScript 对象如何工作的实际机器需要更多的指令来确定 .x 在内存中的位置以及如何获取它。
虚拟机的问题在于它是虚拟的, 它是不存在的。指令不能直接执行,必须在运行时解释。解释代码总是比直接执行代码慢。
这里有一个问题需要权衡。需要在更快的编译时间与更快的运行时间中做一个选择。在许多情况下,更快的编译是一个很好的权衡。用户不太可能关心单个按钮的点击是否需要 20 或 40 毫秒的执行时间,尤其是当按钮只被按下一次时。快速编译 JavaScript,即使生成的代码执行速度较慢,也会让用户更快地查看页面并与页面交互。
有些情况在计算上是昂贵的。诸如游戏、语法高亮之类的场景。在这种情况下,编译和执行机器指令的时间加起来可能会减少总执行时间。那么 JavaScript 是如何处理这些情况的呢?
经常被执行的代码
每当 JavaScript 引擎检测到某个函数执行了很多次时,它就会将该函数交给优化编译器。该编译器将虚拟机指令翻译成实际的机器指令。更重要的是,由于该函数已经运行了多次,优化编译器可以根据之前的运行做出一些假设。换句话说,它可以执行推测优化以生成更快的代码。
如果这些推测后来被证明是错误的,会发生什么? JavaScript引擎可以简单地删除错误的函数,并还原为使用未优化版本。一旦该函数再运行几次,它就可以尝试再次将其传递给优化编译器,这一次它会提供更多可用于推测优化的信息。
既然我们知道频繁运行的函数在优化过程中使用来自先前执行的信息,接下来要探索的是这是什么类型的信息。
翻译问题
JavaScript 中的几乎所有东西都是对象。不幸的是,JavaScript 对象很难让机器处理。让我们看看下面的代码:
function addFive(obj) {
return obj.method() + 5;
}
将函数转换为机器指令非常简单,就像从函数返回一样。但是机器不知道对象是什么,比如访问obj的method属性需要怎么翻译呢?
如果知道 obj 是什么样子会很有帮助,但在 JavaScript 中我们永远无法确定。任何对象都可以添加或删除方法属性。即使method确实存在,我们实际上也不能确定它是否是一个函数,更不用说调用它之后的返回值了。
让我们尝试将上述代码转换为没有对象的 JavaScript 子集,来了解转换为机器指令可能是什么样的。
首先,我们需要一种表示对象的方法。我们还需要一种从其中检索值的方法。在机器代码中支持数组是比较的,所以我们可能会使用这样的表示:
function lookup(obj, name) {
for (var i = 0; i < obj[0].length; i++) {
if (obj[0][i] === name) return i;
}
return -1;
}
参考上述的表示,我们可以尝试对 addFive 进行一个简单的实现
function addFive(obj) {
var propertyIndex = lookup(obj, "method");
var property = propertyIndex < 0
? undefined
: obj[1][propertyIndex];
if (typeof(property) !== "function") {
throw NotAFunction(obj, "method");
}
var callResult = property( obj);
return callResult + 5;
}
当然,这在 obj.method() 返回的不是数字的情况下不能运行,所以我们需要稍微调整一下实现:
function addFive(obj) {
var propertyIndex = lookup(obj, "method");
var property = propertyIndex < 0
? undefined
: obj[1][propertyIndex];
if (typeof(property) !== "function") {
throw NotAFunction(obj, "method");
}
var callResult = property( obj);
if (typeof(callResult) === "string") {
return stringConcat(callResult, "5");
} else if (typeof(callResult !== "number") {
throw NotANumber(callResult);
}
return callResult + 5;
}
这是能运行的,但我希望很明显,如果我们能提前知道 obj 的结构是什么,以及方法的类型是什么,那么这段代码可以跳过几个步骤。
隐藏类
主流的 JavaScript 引擎都以某种方式跟踪对象是什么样的呢?在 Chrome 中,这个概念被称为隐藏类。
让我们从以下代码片段开始:
var obj = {};
obj.x = 1;
obj.toString = function() { return "TODO"; };
delete obj.x;
如果我们将其转换为机器指令,我们将如何在添加和删除新属性时跟踪对象的样子?如果我们使用上一个示例将对象表示为数组的想法,它可能看起来像这样:
var emptyObj__Class = [
null,
[],
[]
];
var obj = [
emptyObj__Class,
[]
];
var obj_X__Class = [
emptyObj__Class,
["x"],
["number"]
];
obj[0] = obj_X__Class;
obj[1].push(1);
var obj_X_ToString__Class = [
obj_X__Class,
["toString"],
["function"]
];
obj[0] = obj_X_ToString__Class;
obj[1].push(function() { return "TODO"; });
var obj_ToString__Class = [
null,
["toString"],
["function"]
];
obj[0] = obj_ToString__Class;
obj[1] = [obj[1][1]];
如果我们要生成这样的虚拟机指令,我们现在就有了一种方法来跟踪对象在任何给定时间的样子。然而,这本身并不能真正帮助我们。我们需要将这些信息存储在有价值的地方。
内联缓存
每当 JavaScript 代码对对象执行属性访问时,JavaScript 引擎都会将该对象的隐藏类以及查找结果(属性名称到索引的映射)存储在缓存中。这些缓存被称为内联缓存,它们有两个重要目的:
- 在执行字节码时,如果所涉及的对象具有缓存中的隐藏类,它们会加速属性访问。
- 在优化期间,它们包含有关访问对象属性时所涉及的对象类型的信息,这有助于优化编译器生成特别适合这些类型的代码。
内联缓存对它们存储信息的隐藏类的数量有限制。这可以保留内存,但也确保在缓存中执行查找速度很快。如果从内联缓存中检索索引比从隐藏类中检索索引花费的时间更长,则缓存没有任何用处。
据我所知, Chrome在中,内联缓存最多会跟踪 4 个隐藏类。在此之后,内联缓存将被禁用,信息将存储在全局缓存中。全局缓存的大小也有限制,一旦达到限制,新条目将覆盖旧条目。
为了最好地利用内联缓存并帮助优化编译器,应该尝试编写仅对单一类型的对象执行属性访问的函数。不仅如此,生成的代码的性能将是次优的
一种单独且重要的优化是内联。简而言之,这种优化用被调用函数的实现代替了函数调用。举个例子:
function map(fn, list) {
var newList = [];
for (var i = 0; i < list.length; i++) {
newList.push(fn(list[i]));
}
return newList;
}
function incrementNumbers(list) {
return map(function(n) { return n + 1; }, list);
}
incrementNumbers([1, 2, 3]);
内联后,代码最终可能看起来像这样:
function incrementNumbers(list) {
var newList = [];
var fn = function(n) { return n + 1; };
for (var i = 0; i < list.length; i++) {
newList.push(fn(list[i]));
}
return newList;
}
incrementNumbers([1, 2, 3]);
这样做的一个好处是删除了函数调用。更大的好处是 JavaScript 引擎现在可以更深入地了解函数的实际作用。基于这个新版本,JavaScript 引擎可能会决定再次执行内联:
function incrementNumbers(list) {
var newList = [];
for (var i = 0; i < list.length; i++) {
newList.push(list[i] + 1);
}
return newList;
}
incrementNumbers([1, 2, 3]);
另一个函数调用已被删除。更重要的是,优化器现在可能会推测 incrementNumbers 只会以数字列表作为参数被调用。它还可能决定内联 incrementNumbers([1, 2, 3]) 调用本身,并发现 list.length 为 3,这又可能导致:
var list = [1, 2, 3];
var newList = [];
newList.push(list[0] + 1);
newList.push(list[1] + 1);
newList.push(list[2] + 1);
list = newList;
简而言之,内联可以实现跨函数边界无法执行的优化。
但是,可以内联的内容是有限的。由于代码重复,内联会导致更大的函数,这需要额外的内存。 JavaScript 引擎对一个函数在完全跳过内联之前可以达到的大小有一个预算。
一些函数调用也很难内联。特别是当一个函数作为参数传入时。
此外,作为参数传递的函数很难内联,除非它总是同一个函数。虽然这可能会让您觉得这是一件奇怪的事情,但由于内联,最终可能会出现这种情况。
JavaScript 引擎有许多提高运行时性能的技巧,比这里介绍的要多得多。但是,本文中描述的优化适用于大多数浏览器,并且很容易验证它们是否被应用。因此,当我们尝试提高 Elm 的运行时性能时,我们将主要关注这些优化。
What’s up with monomorphism
Shapes and inline caches
Optimizing prototypes
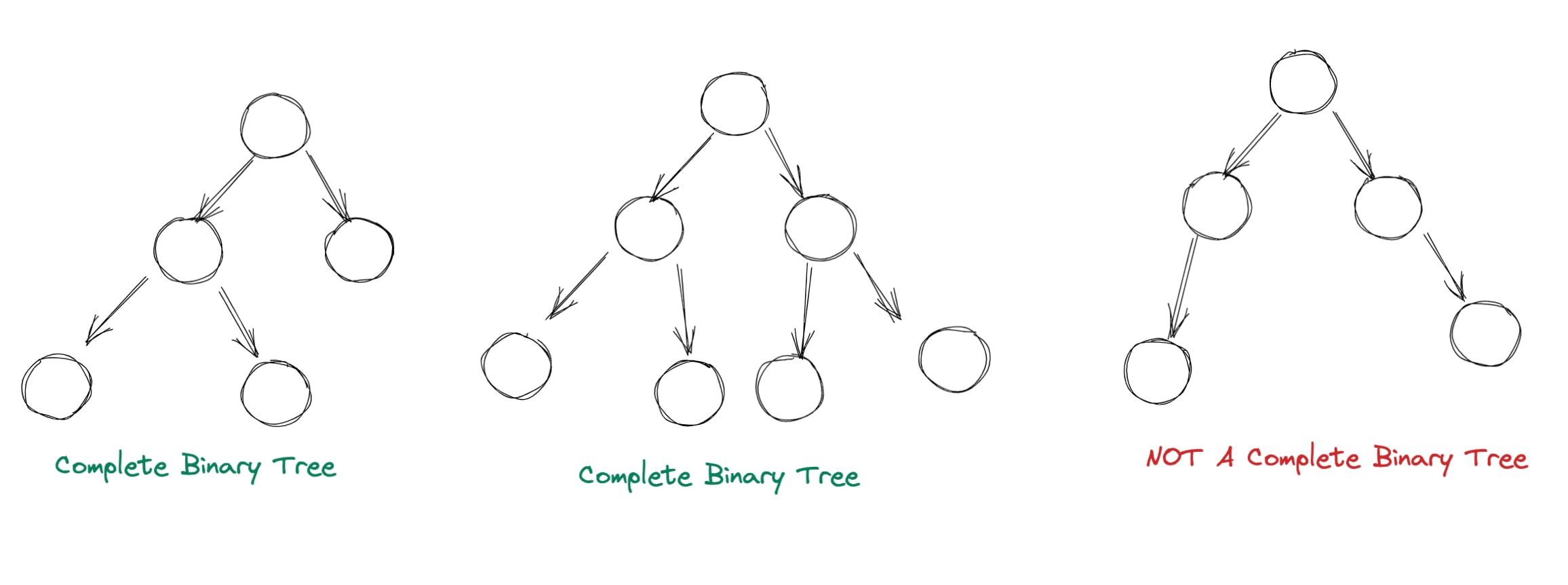 2.每个节点都满足“堆属性”:堆属性本质上意味着对于任何给定的节点 C,如果 P 是 C 的父节点,则:
2.每个节点都满足“堆属性”:堆属性本质上意味着对于任何给定的节点 C,如果 P 是 C 的父节点,则: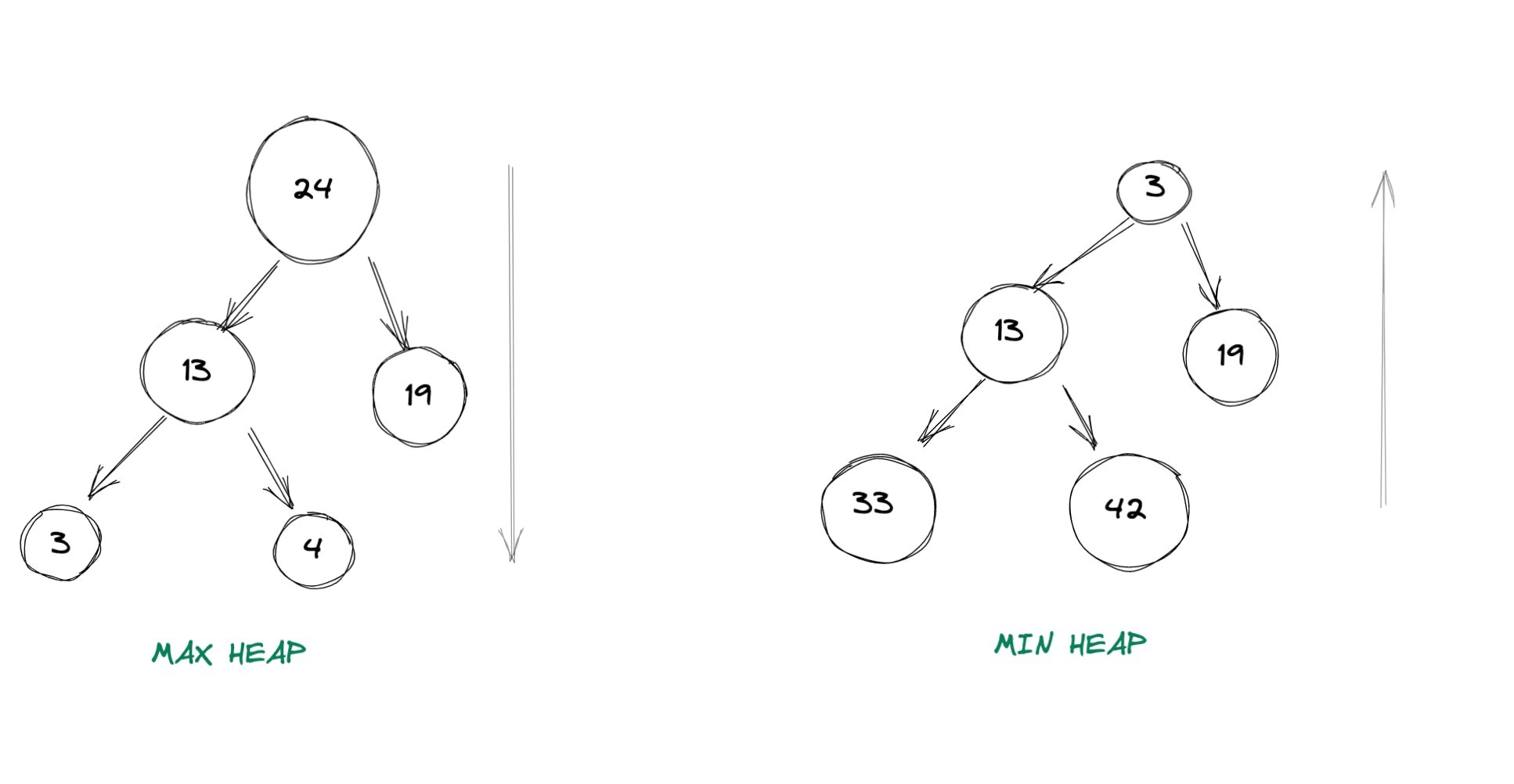
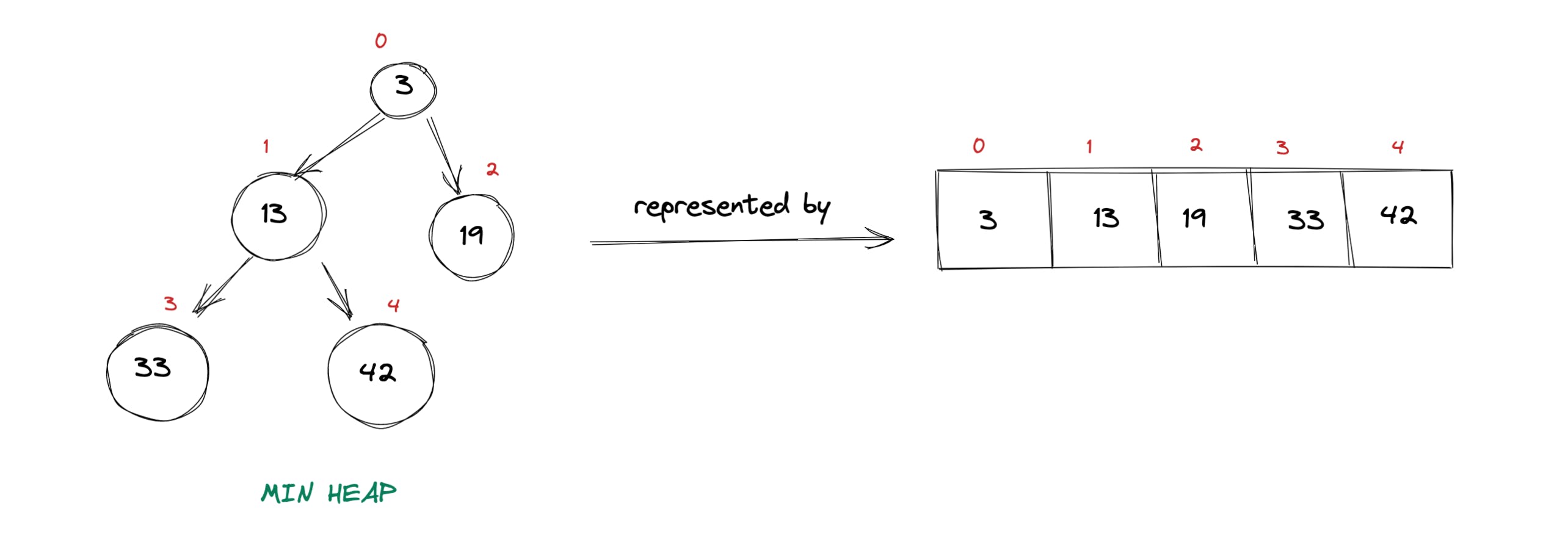 这里要注意的关键是父节点和子节点之间的关系。如果仔细观察上图,我们可以推断出以下内容:
这里要注意的关键是父节点和子节点之间的关系。如果仔细观察上图,我们可以推断出以下内容: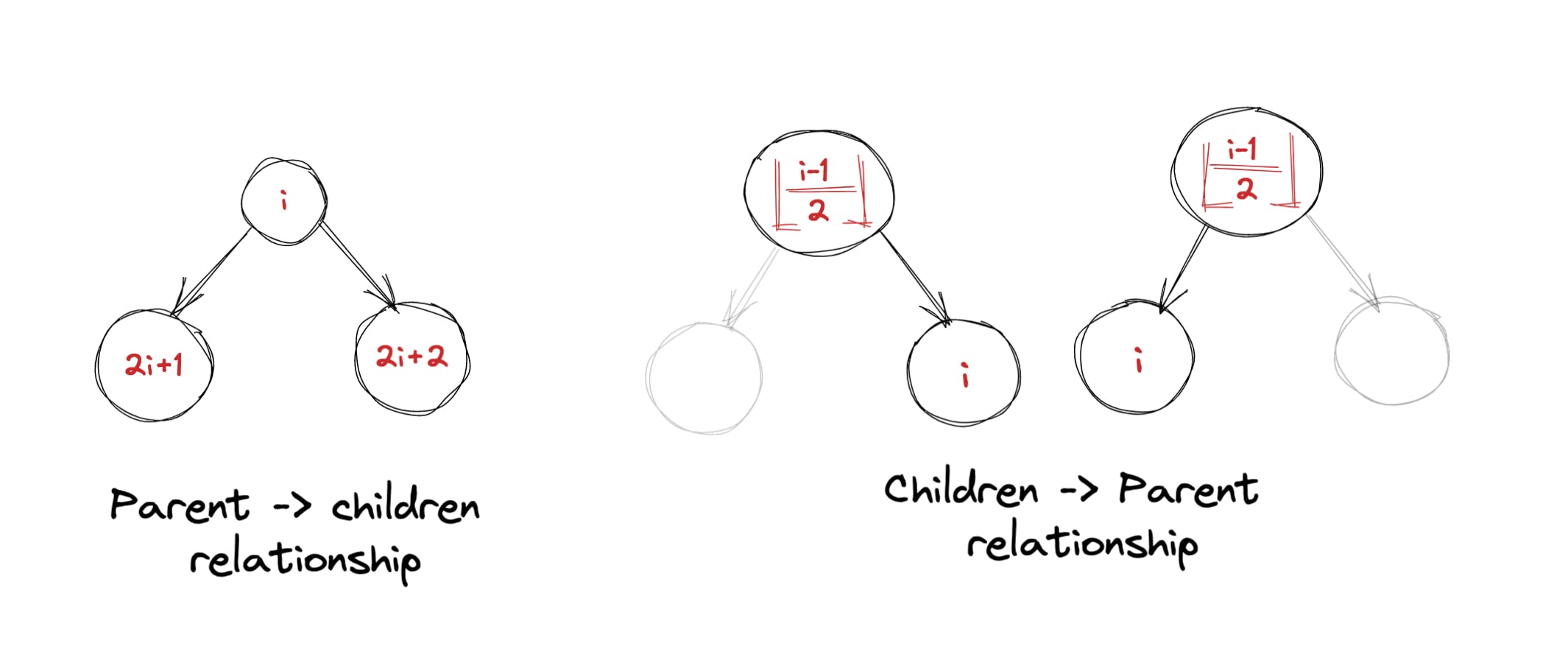
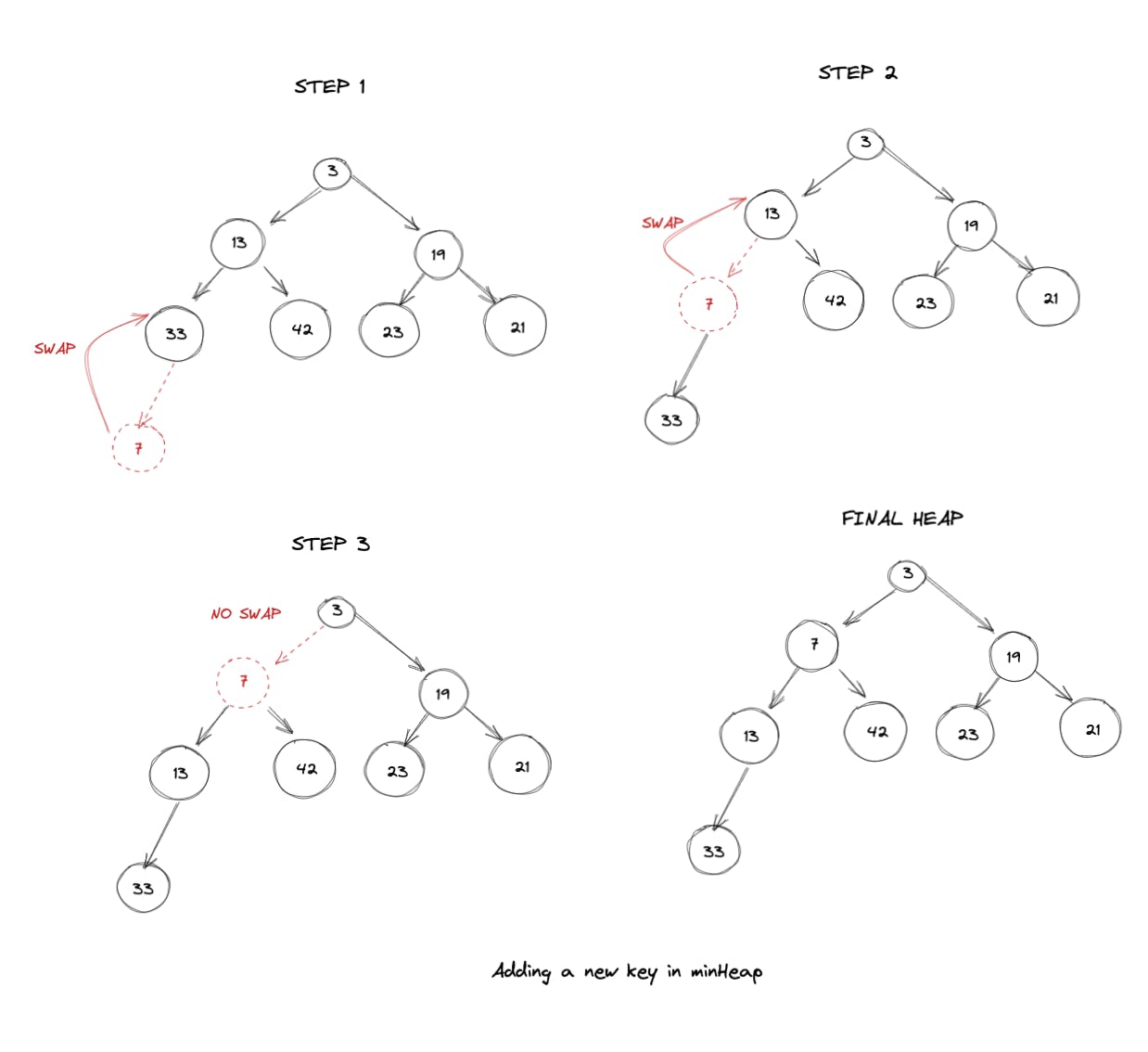 代码如下
代码如下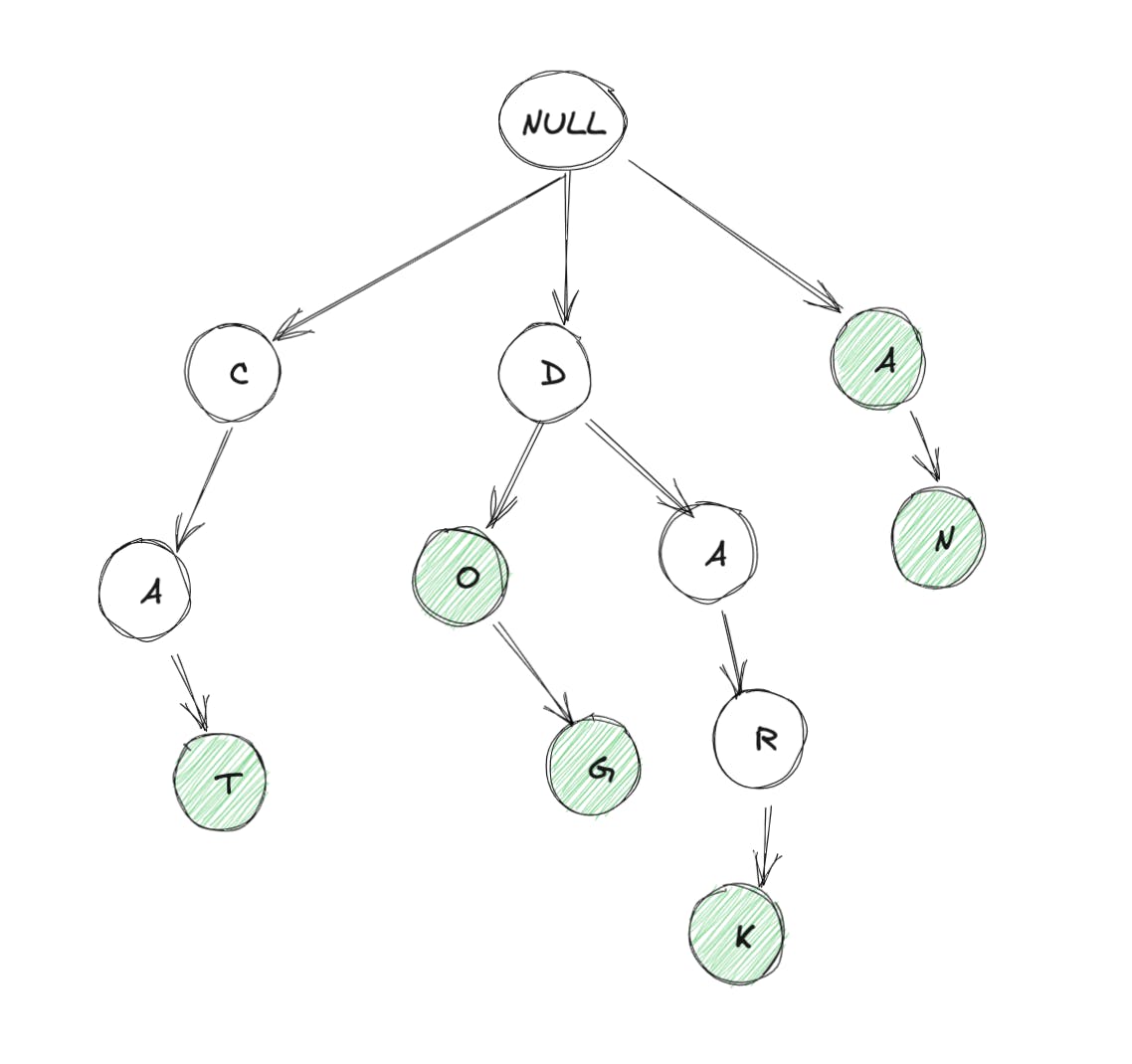 需要注意的事项:
需要注意的事项: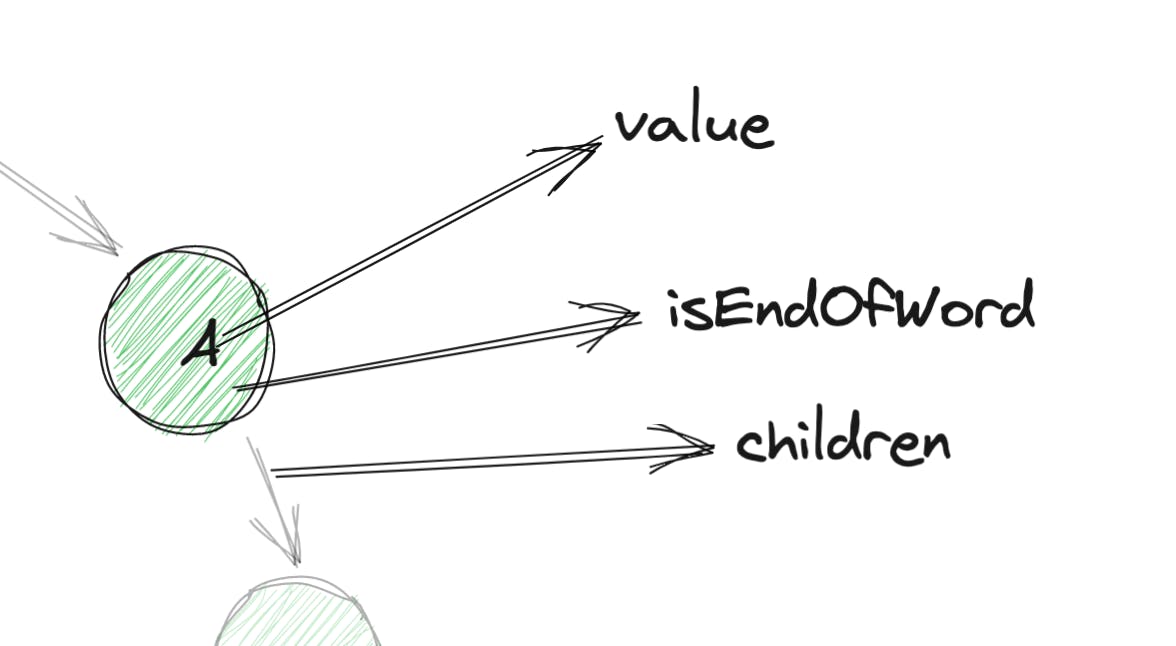 所以现在更有意义了。这是最终的代码:
所以现在更有意义了。这是最终的代码: