不久前,React Router 库更新到了第 6 版,随之而来的是一些有趣的变化,本文将讲述React Router 6的一些新特性及使用的案例。
接下来是一些准备工作:
- 首先需要创建一个新的 React 项目(例如 create-react-app)。然后,按照官方文档安装 React Router。
yarn add react-router-dom@latest
 我们这里安装的是6.0.2版本。
我们这里安装的是6.0.2版本。 - 第一个实现细节将告诉我们的 React 应用程序我们想要使用 React Router。因此,在 React 项目的顶级文件(例如 index.js)中导入 Router 组件,其中 React 使用 ReactDOM API 挂载到 HTML:
import React from 'react';
import ReactDOM from 'react-dom';
import { BrowserRouter } from 'react-router-dom';
import App from './App';
ReactDOM.render(
<BrowserRouter>
<App />
</BrowserRouter>,
document.getElementById('root')
);
从这里开始,我们将在 App.js 文件中继续我们的实现。
匹配路由
首先,我们将使用 React Router 的 Link 组件在我们的 App 组件中实现导航。我不建议使用内联样式,因此请根据你的 React 项目选择合适的样式策略和样式方法:
import { Link } from 'react-router-dom';
const App = () => {
return (
<>
<h1>React Router</h1>
<Navigation />
</>
);
};
const Navigation = () => {
return (
<nav
style={{
borderBottom: 'solid 1px',
paddingBottom: '1rem',
}}
>
<Link to="/home">Home</Link>
<Link to="/users">Users</Link>
</nav>
);
};
 当你在浏览器中启动 React 应用程序时,你应该能够单击两个 Link 组件,这些组件应该将你导航到各自的路由。单击这些链接时,可通过检查浏览器的当前 URL 来确认。接下来,我们需要使用 React Router 的 Route 组件将路由映射到实际渲染:
当你在浏览器中启动 React 应用程序时,你应该能够单击两个 Link 组件,这些组件应该将你导航到各自的路由。单击这些链接时,可通过检查浏览器的当前 URL 来确认。接下来,我们需要使用 React Router 的 Route 组件将路由映射到实际渲染:
import { Routes, Route, Link } from 'react-router-dom';
const App = () => {
return (
<>
<h1>React Router</h1>
<Navigation />
<Routes>
<Route path="home" element={<Home />} />
<Route path="users" element={<Users />} />
</Routes>
</>
);
};
const Navigation = () => {
return (
<nav
style={{
borderBottom: 'solid 1px',
paddingBottom: '1rem',
}}
>
<Link to="/home">Home</Link>
<Link to="/users">Users</Link>
</nav>
);
};
你可以通过检查它们各自的 to 和 path 属性来查看 Link 和 Route 组件之间的直接匹配。当路由匹配时,每个 Route 组件都会渲染一个 React 元素。由于我们在这里渲染一个 React 元素,我们也可以传递 React props。缺少的是相应功能组件的声明:
const Home = () => {
return (
<main style={{ padding: '1rem 0' }}>
<h2>Home</h2>
</main>
);
};
const Users = () => {
return (
<main style={{ padding: '1rem 0' }}>
<h2>Users</h2>
</main>
);
};
返回浏览器时,你应该能够在看到 Home 和 Users 组件的同时从一个页面导航到另一个页面(此处:从 /home 到 /users 路由)。基本上这就是 React Router 的本质:设置 Link 组件并将它们与 Route 组件匹配。链接与路由是多对一的关系,因此你的应用程序中可以有多个链接链接到同一个路由。
布局路由、索引路由、无匹配路由
接下来,你将看到新的 Home 和 Users 组件如何共享相同的布局。作为 React 开发人员,直觉上我们会从 Home 和 Users 组件中提取一个带有样式的新组件,以避免重复。在这个新组件中,我们将使用 React 的 children 属性将组件组合在一起。第一步,将样式提取到它自己的组件中:
const Home = () => {
return (
<>
<h2>Home</h2>
</>
);
};
const Users = () => {
return (
<>
<h2>Users</h2>
</>
);
};
const Layout = ({ children }) => {
return <main style={{ padding: '1rem 0' }}>{children}</main>;
};
其次,在 App 组件中渲染它。通过使用 React 的子级,Layout 组件应该渲染匹配的封闭子路由:
import { Routes, Route, Link } from 'react-router-dom';
const App = () => {
return (
<>
<h1>React Router</h1>
<Navigation />
<Routes>
<Layout>
<Route path="home" element={<Home />} />
<Route path="users" element={<Users />} />
</Layout>
</Routes>
</>
);
};
const Navigation = () => {
return (
<nav
style={{
borderBottom: 'solid 1px',
paddingBottom: '1rem',
}}
>
<Link to="/home">Home</Link>
<Link to="/users">Users</Link>
</nav>
);
};
const Home = () => {
return (
<>
<h2>Home</h2>
</>
);
};
const Users = () => {
return (
<>
<h2>Users</h2>
</>
);
};
const Layout = ({ children }) => {
return <main style={{ padding: '1rem 0' }}>{children}</main>;
};
但是你会看到这在 React Router 中是不允许的,你会得到一个异常说:<Routes> 的所有组件子项必须是 <Route> 或 <React.Fragment>。解决此问题的一种常见方法是在每个组件中单独使用 Layout 组件(类似于我们之前使用的)或在每个 Route 组件中(如下例所示):
const App = () => {
return (
<>
...
<Routes>
<Route path="home" element={<Layout><Home /></Layout>} />
<Route path="users" element={<Layout><Users /></Layout>} />
</Routes>
</>
);
};
然而,这给 React 应用程序增加了不必要的冗余。因此,我们将使用所谓的 Layout Route,而不是复制 Layout 组件,它不是实际的路由,而只是一种方法,可以让一组 Route 中的每个 Route 组件的元素具有相同的周围样式:
const App = () => {
return (
<>
...
<Routes>
<Route element={<Layout />}>
<Route path="home" element={<Home />} />
<Route path="users" element={<Users />} />
</Route>
</Routes>
</>
);
};
如你所见,可以将 Route 组件嵌套在另一个 Route 组件中——而前者成为所谓的嵌套路由。现在不再在 Layout 组件中使用 React 的子组件,而是使用 React Router 的 Outlet 组件作为等效组件:
import { Routes, Route, Outlet, Link } from 'react-router-dom';
...
const Layout = () => {
return (
<main style={{ padding: '1rem 0' }}>
<Outlet />
</main>
);
};
本质上,Layout 组件中的 Outlet 组件插入了父路由(这里:Layout 组件)的匹配子路由(这里:Home 或 Users 组件)。毕竟,使用 Layout Route 可以帮助你为集合中的每个 Route 组件提供相同的布局(例如,CSS 样式,HTML 结构)。
从这里开始,你可以更进一步,将 App 组件的所有实现细节(标题、导航)移动到这个新的 Layout 组件中。此外,我们可以与 NavLink 组件交换链接,以实现所谓的活动链接——向用户显示当前活动的路线。因此,当将新的 NavLink 组件与函数一起使用时,我们可以访问其style和 className props中的 isActive 标志:
import { Routes, Route, Link, NavLink, Outlet } from 'react-router-dom';
const App = () => {
return (
<>
<h1>React Router</h1>
<Navigation />
<Routes>
<Route element={<Layout />}>
<Route path="home" element={<Home />} />
<Route path="users" element={<Users />} />
</Route>
</Routes>
</>
);
};
const Navigation = () => {
return (
<nav
style={{
borderBottom: 'solid 1px',
paddingBottom: '1rem',
}}
>
<Link to="/home">Home</Link>
<Link to="/users">Users</Link>
</nav>
);
};
const Home = () => {
return (
<>
<h2>Home</h2>
</>
);
};
const Users = () => {
return (
<>
<h2>Users</h2>
</>
);
};
const Layout = () => {
const style = ({ isActive }) => ({
fontWeight: isActive ? 'bold' : 'normal',
});
return (
<>
<h1>React Router</h1>
<nav
style={{
borderBottom: 'solid 1px',
paddingBottom: '1rem',
}}
>
<NavLink to="/home" style={style}>Home</NavLink>
<NavLink to="/users" style={style}>Users</NavLink>
</nav>
<main style={{ padding: '1rem 0' }}>
<Outlet />
</main>
</>
);
};
接下来你可能已经注意到这个 React 应用程序缺少一个基本路由。虽然我们有 /home 和 /users 路由,但没有 / 路由。你也会在浏览器的开发人员工具中看到此警告:没有路由匹配位置“/”。因此,每当用户访问 / 路由时,我们都会创建一个所谓的索引路由作为回退。此回退路由的元素可以是新组件或任何已匹配的路由(例如,Home 应为路由 / 和 /home 呈现,如下例所示):
const App = () => {
return (
<Routes>
<Route element={<Layout />}>
<Route index element={<Home />} />
<Route path="home" element={<Home />} />
<Route path="users" element={<Users />} />
</Route>
</Routes>
);
};
当父路由匹配但没有子路由匹配时,你可以将索引路由视为默认路由。接下来,如果用户导航到不匹配的路由(例如 /about),我们将添加一个所谓的 No Match Route(也称为 Not Found Route),它相当于网站的 404 页面:
const App = () => {
return (
<Routes>
<Route element={<Layout />}>
<Route index element={<Home />} />
<Route path="home" element={<Home />} />
<Route path="users" element={<Users />} />
<Route path="*" element={<NoMatch />} />
</Route>
</Routes>
);
};
const NoMatch = () => {
return (<p>There's nothing here: 404!</p>);
};
到目前为止,在使用 Routes 组件作为 Route 组件集合的容器时,通过使用 Layout Routes、Index Routes 和 No Match Routes 展示了 React Router 的其他最佳实践。如你所见,也可以将 Route 组件嵌套到 Route 组件中。�下面我们接着了解有关嵌套路由的更多信息。
动态且嵌套的路由
接下来我们将用实现细节来装饰用户组件。首先,我们将在我们的 App 组件中初始化一个项目列表(这里是:用户)。该列表只是示例数据,但它也可以在 React 中从远程 API 获取。其次,我们将用户作为props传递给用户组件:
const App = () => {
const users = [
{ id: '1', fullName: 'Robin Wieruch' },
{ id: '2', fullName: 'Sarah Finnley' },
];
return (
<Routes>
<Route element={<Layout />}>
<Route index element={<Home />} />
<Route path="home" element={<Home />} />
<Route path="users" element={<Users users={users} />} />
<Route path="*" element={<NoMatch />} />
</Route>
</Routes>
);
};
Users 组件成为 React 中的列表组件,因为它遍历每个用户并为其返回 JSX。在这种情况下,它不仅仅是一个列表,因为我们将 React Router 的 Link 组件添加到组合中。 Link 组件中的相对路径提示相应的动态(此处:/${user.id})尚未嵌套(此处:/${user.id} 嵌套在 /users 中)路由:
const Users = ({ users }) => {
return (
<>
<h2>Users</h2>
<ul>
{users.map((user) => (
<li key={user.id}>
<Link to={`/users/${user.id}`}>
{user.fullName}
</Link>
</li>
))}
</ul>
</>
);
};
通过拥有这个新的动态嵌套路由,我们需要在 App 组件中为它创建一个匹配的嵌套路由组件。首先,由于它是 /users 路由的所谓嵌套路由(或子路由),我们可以将它嵌套在相应的父路由组件中。此外,由于它是所谓的动态路由,它使用定义为 :userId 的动态路由,而用户的标识符则动态匹配(例如,id 为 '1' 的用户将与 /users/1 匹配):
const App = () => {
const users = [
{ id: '1', fullName: 'Robin Wieruch' },
{ id: '2', fullName: 'Sarah Finnley' },
];
return (
<Routes>
<Route element={<Layout />}>
<Route index element={<Home />} />
<Route path="home" element={<Home />} />
<Route path="users" element={<Users users={users} />}>
<Route path=":userId" element={<User />} />
</Route>
<Route path="*" element={<NoMatch />} />
</Route>
</Routes>
);
};
之前,当我们介绍将 /home 和 /users 路由作为其子路由的父布局路由时,我们已经了解了嵌套路由。当我们进行此更改时,我们必须使用父路由中的 Outlet 组件来渲染匹配的子路由。同样的情况在这里再次发生,因为用户组件也必须渲染它的嵌套路由:
const Users = ({ users }) => {
return (
<>
<h2>Users</h2>
<ul>...</ul>
<Outlet />
</>
);
};
接下来,我们将声明缺少的 User 组件,只要用户的标识符在 URL 中匹配,该组件就会通过 Users 组件中的 Outlet 嵌套。因此,我们可以使用 React Router 的 useParams Hook 从 URL 中获取相应的 userId(等于 :userId):
import {
...
useParams,
} from 'react-router-dom';
...
const User = () => {
const { userId } = useParams();
return (
<>
<h2>User: {userId}</h2>
<Link to="/users">Back to Users</Link>
</>
);
};
我们再次看到了如何通过将一个 Route 组件(或多个 Route 组件)嵌套在另一个 Route 组件中来创建嵌套路由。前者是嵌套的子路由,后者是渲染封闭组件的父路由,该组件必须使用 Outlet 组件来渲染实际匹配的子路由。
我们还看到了如何通过在路由的路径属性(例如:userId)中使用冒号来创建动态路由。本质上, :userId 充当任何标识符的星号。在我们的例子中,我们使用 Link 组件将用户导航到 /users/:userId 路由,其中 :userId 代表实际用户的标识符。最后,我们总是可以通过使用 React Router 的 useParams Hook 从 URL 中获取动态路径(称为参数或 params)。
React Router中的相关链接
最新版本的 React Router 带有所谓的相对链接。我们将通过查看用户组件及其用于链接组件的绝对 /users/${user.id} 路径来研究这个概念。在之前版本的 React Router 中,需要指定整个路径。但是,在此版本中,你可以仅使用嵌套路径作为相对路径:
const Users = ({ users }) => {
return (
<>
<h2>Users</h2>
<ul>
{users.map((user) => (
<li key={user.id}>
<Link to={user.id}>
{user.fullName}
</Link>
</li>
))}
</ul>
</>
);
};
由于 Users 组件用于 /users 路由,因此 Users 组件中的 Link 知道其当前位置,不需要创建绝对路径的整个顶级部分。相反,它知道 /users 并且只是附加 :userId 作为它的相对路径。
声明式和程序式导航
到目前为止,我们只在使用 Link 或 NavLink 组件时使用了声明式导航。但是,在某些情况下,你希望能够通过 JavaScript 以编程方式导航用户。我们将通过实现一个可以在 User 组件中删除用户的功能来展示这个场景。在删除后,用户应该从 User 组件导航到 Users 组件(从 /users/:userId 到 /users)。
我们将通过使用 React 的 useState Hook 创建一个有状态的 users 值来开始这个实现,然后实现一个事件处理程序,该处理程序使用标识符从用户中删除用户:
import * as React from 'react';
...
const App = () => {
const [users, setUsers] = React.useState([
{ id: '1', fullName: 'Robin Wieruch' },
{ id: '2', fullName: 'Sarah Finnley' },
]);
const handleRemoveUser = (userId) => {
setUsers((state) => state.filter((user) => user.id !== userId));
};
return (
<Routes>
<Route element={<Layout />}>
<Route index element={<Home />} />
<Route path="home" element={<Home />} />
<Route path="users" element={<Users users={users} />}>
<Route
path=":userId"
element={<User onRemoveUser={handleRemoveUser} />}
/>
</Route>
<Route path="*" element={<NoMatch />} />
</Route>
</Routes>
);
};
在我们将事件处理程序作为回调处理程序传递给 User 组件后,我们可以在那里使用它作为内联处理程序来通过标识符删除特定用户:
const User = ({ onRemoveUser }) => {
const { userId } = useParams();
return (
<>
<h2>User: {userId}</h2>
<button type="button" onClick={() => onRemoveUser(userId)}>
Remove
</button>
<Link to="/users">Back to Users</Link>
</>
);
};
一旦用户被删除,我们可以使用 React Router 的 useNavigate Hook,它允许我们以编程方式将用户导航到另一个路由(这里:/users):
import * as React from 'react';
import {
...
useNavigate,
} from 'react-router-dom';
const App = () => {
const navigate = useNavigate();
const [users, setUsers] = React.useState([
{ id: '1', fullName: 'Robin Wieruch' },
{ id: '2', fullName: 'Sarah Finnley' },
]);
const handleRemoveUser = (userId) => {
setUsers((state) => state.filter((user) => user.id !== userId));
navigate('/users');
};
return (...);
};
在这种情况下,删除操作是同步发生的,因为用户只是客户端的一个有状态值。但是,如果用户是数据库中的实体,则必须发出异步请求才能删除它。一旦这个操作成功(例如:promise是 resolved时),用户就会被导航到 /users 路由。你可以通过在 React 中设置一个虚假的 API 来自己尝试这个场景,而不使用实际的服务器。
搜索参数
浏览器中的 URL 不仅包含路径,还包含一个可选的查询字符串(在 React Router 中称为搜索参数),它以键/值对的形式出现在 ? URL 中的分隔符。例如,/users?name=robin 将是一个带有一对搜索参数的 URL,其中键是名称,值是 robin。以下示例将其显示为实现:
import * as React from 'react';
import {
...
useSearchParams,
} from 'react-router-dom';
...
const Users = ({ users }) => {
const [searchParams, setSearchParams] = useSearchParams();
const searchTerm = searchParams.get('name') || '';
const handleSearch = (event) => {
const name = event.target.value;
if (name) {
setSearchParams({ name: event.target.value });
} else {
setSearchParams({});
}
};
return (
<>
<h2>Users</h2>
<input
type="text"
value={searchTerm}
onChange={handleSearch}
/>
<ul>
{users
.filter((user) =>
user.fullName
.toLowerCase()
.includes(searchTerm.toLocaleLowerCase())
)
.map((user) => (
<li key={user.id}>
<Link to={user.id}>{user.fullName}</Link>
</li>
))}
</ul>
<Outlet />
</>
);
};
首先,我们使用 React Router 的 useSearchParams Hook 从 URL 中读取当前搜索参数(请参阅 searchParams 上的 get() 方法),同时还将搜索参数写入 URL(请参阅 setSearchParams() 函数)。虽然我们使用前者按键获取搜索参数(此处:“name”)来控制输入字段,但我们使用后者在 URL 中按键设置搜索参数。在输入字段中键入。在其核心,React Router 的 useSearchParams Hook 与 React 的 useState Hook 相同,区别在于该状态是 URL 状态,而不是 React 中的本地状态。最后我们使用搜索参数来过滤用户的实际列表以完成此功能。
毕竟,在你的 URL 中包含搜索参数可以让你与他人共享更具体的 URL。如果你在一个搜索黑色鞋子的电子商务网站上,你可能希望共享整个 URL(例如 myecommerce.com/shoes?color=black)而不仅仅是路径(例如 myecommerce.com/shoes)。
React Router 是 React 最常用的第三方库之一。它的核心功能是将 Link 组件映射到 Route 组件,这使开发人员无需向 Web 服务器发出请求即可实现客户端路由。然而,除了这个核心功能之外,它还是一个成熟的路由库,它支持声明式嵌套路由、动态路由、导航、活动链接,还可以通过 URL 进行编程导航和搜索。
react-router
CRA
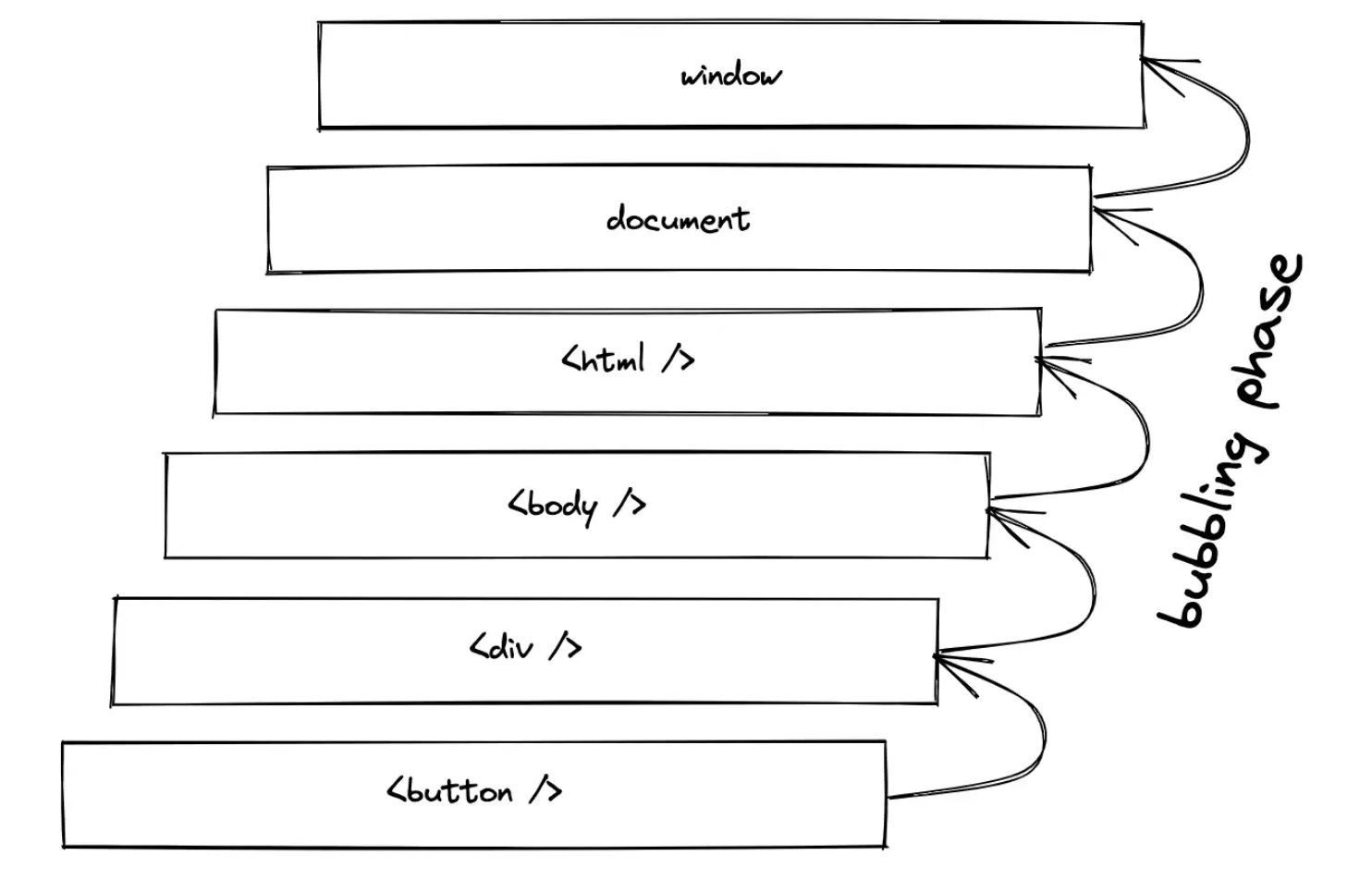 在下一个示例中尝试一下,当单击内部 HTML 元素时,两个事件处理程序都会被触发。如果单击外部 HTML 元素,则仅触发外部元素的事件处理程序:
在下一个示例中尝试一下,当单击内部 HTML 元素时,两个事件处理程序都会被触发。如果单击外部 HTML 元素,则仅触发外部元素的事件处理程序: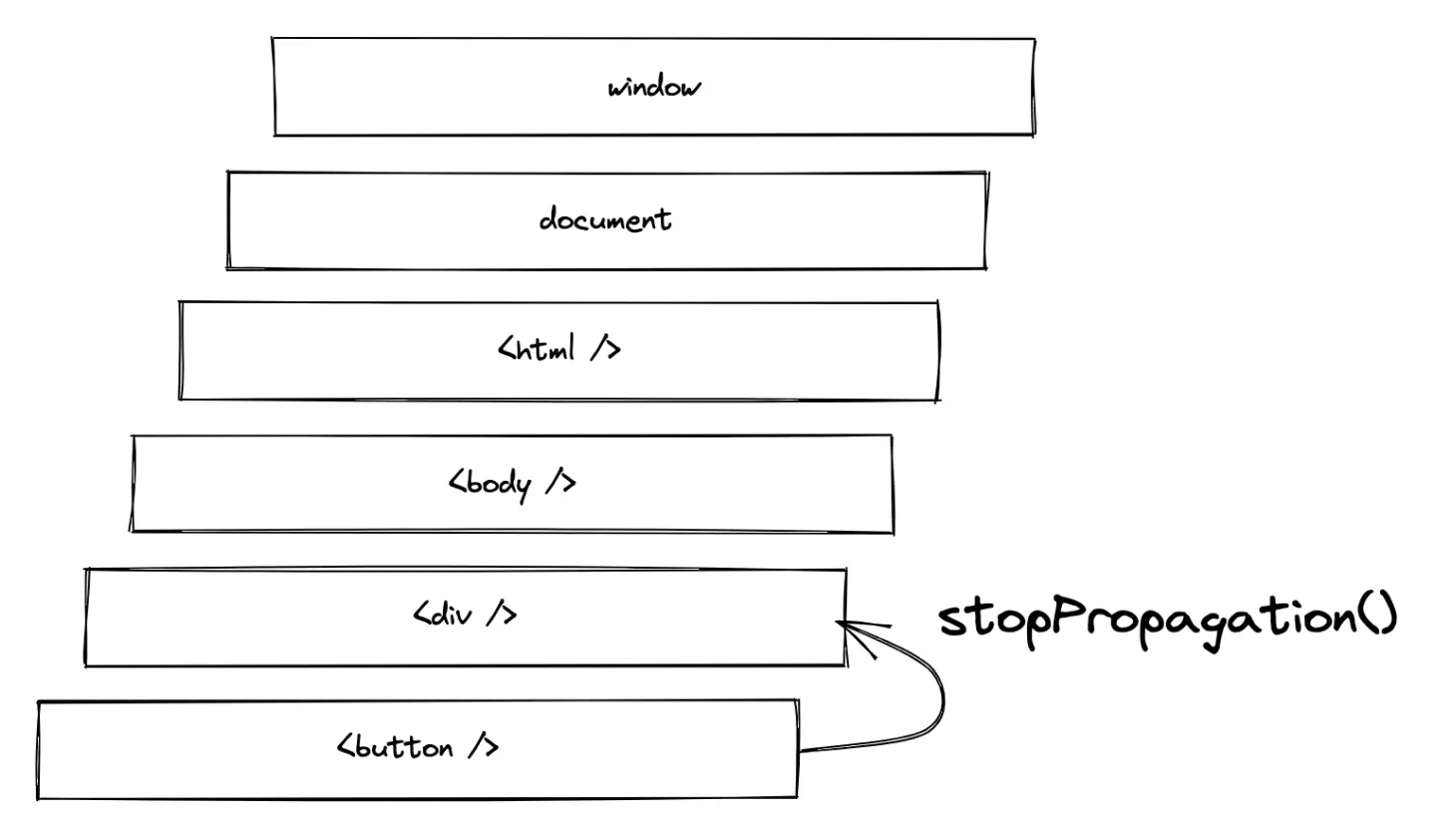 反之,当容器元素被显式点击时(在这种情况下不太可能没有任何进一步的样式),只有容器的事件处理程序会触发。这里容器元素上的 stopPropagation() 有点多余,因为它上面没有事件处理程序。
反之,当容器元素被显式点击时(在这种情况下不太可能没有任何进一步的样式),只有容器的事件处理程序会触发。这里容器元素上的 stopPropagation() 有点多余,因为它上面没有事件处理程序。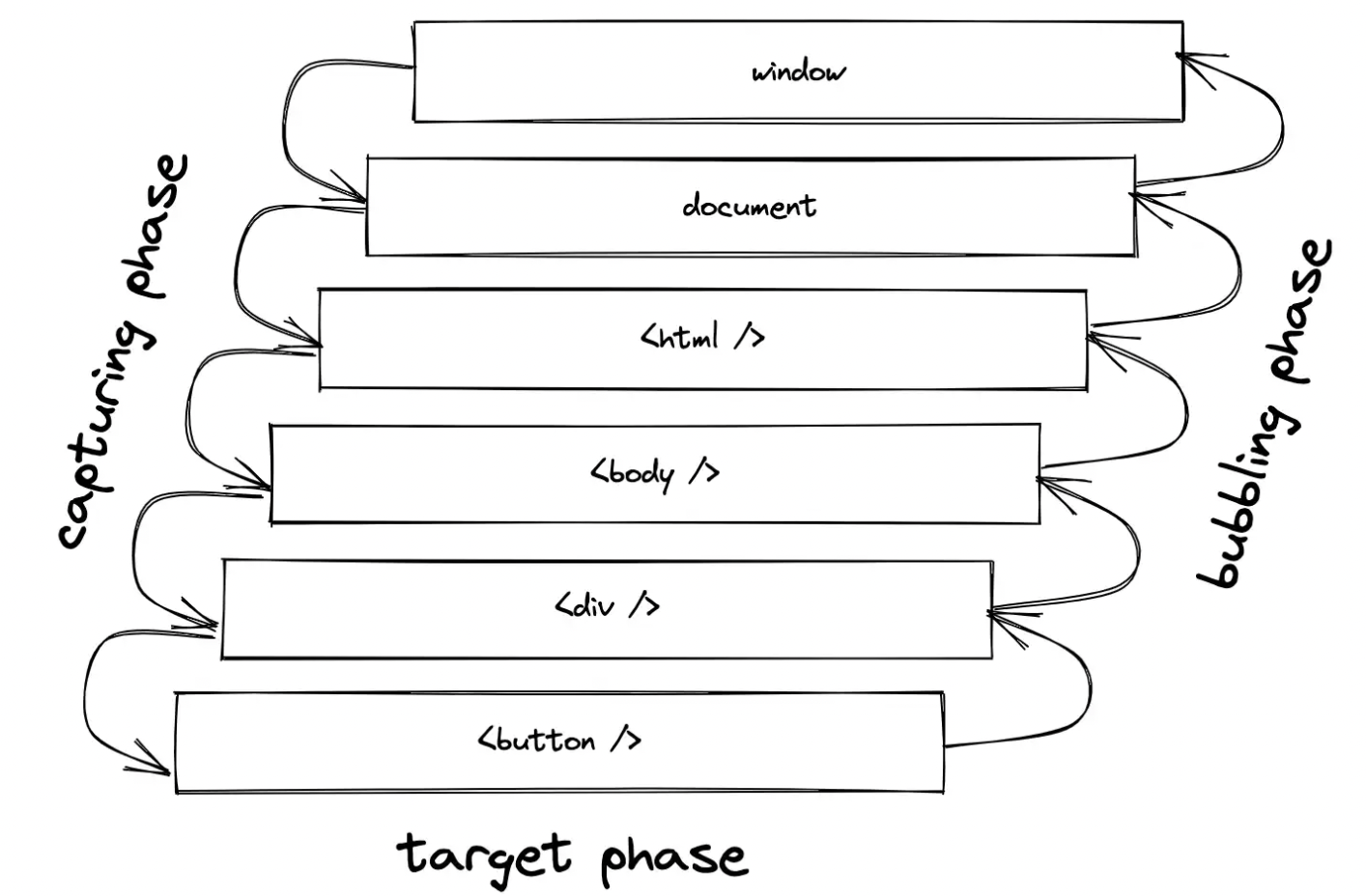
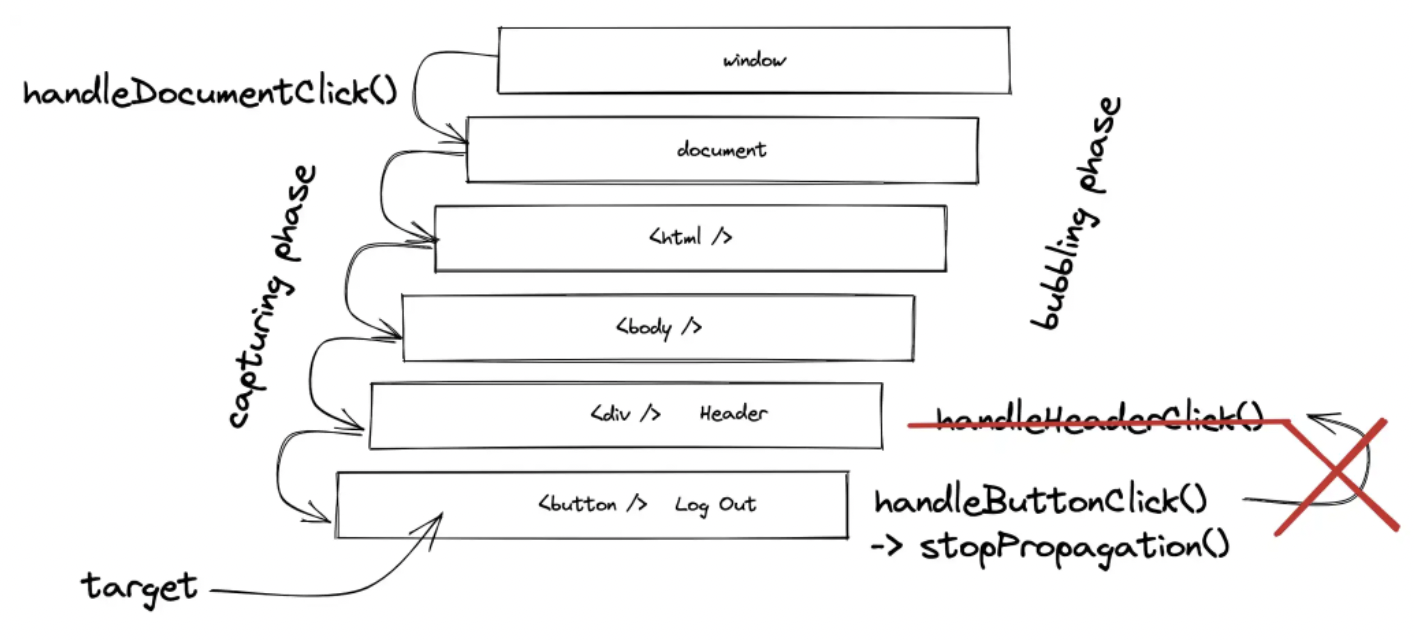

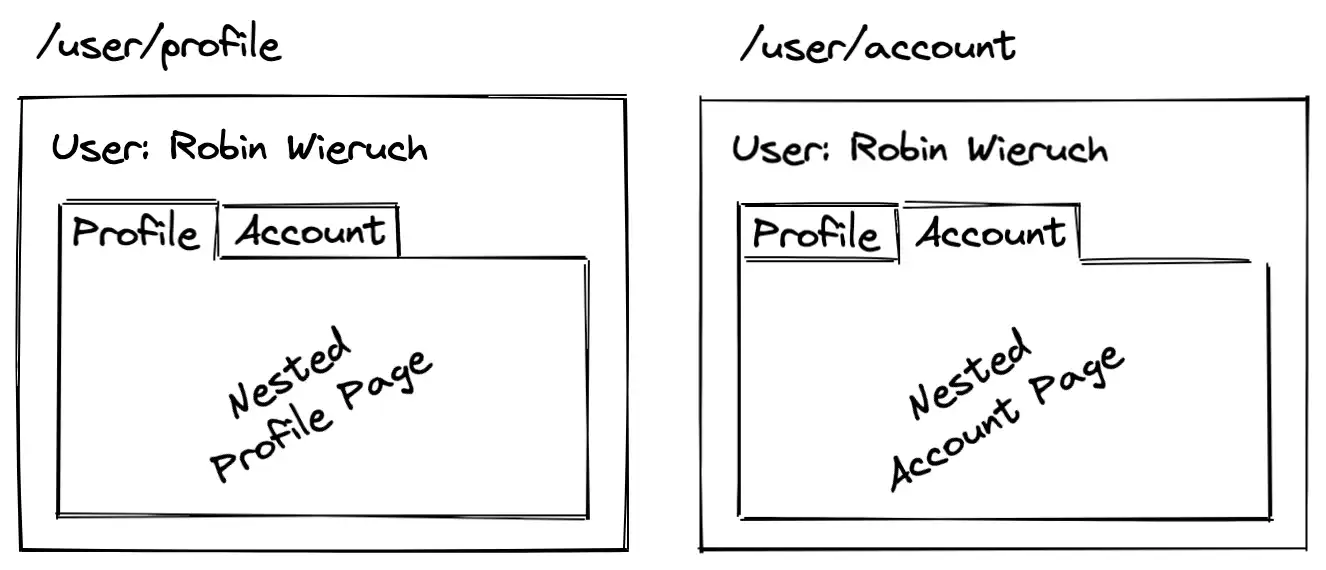 下面我们将使用 React Router 重新创建这个场景。为了说明这是如何工作的,以及如何自己在 React 中逐步实现嵌套路由,我们将从以下示例开始:
下面我们将使用 React Router 重新创建这个场景。为了说明这是如何工作的,以及如何自己在 React 中逐步实现嵌套路由,我们将从以下示例开始: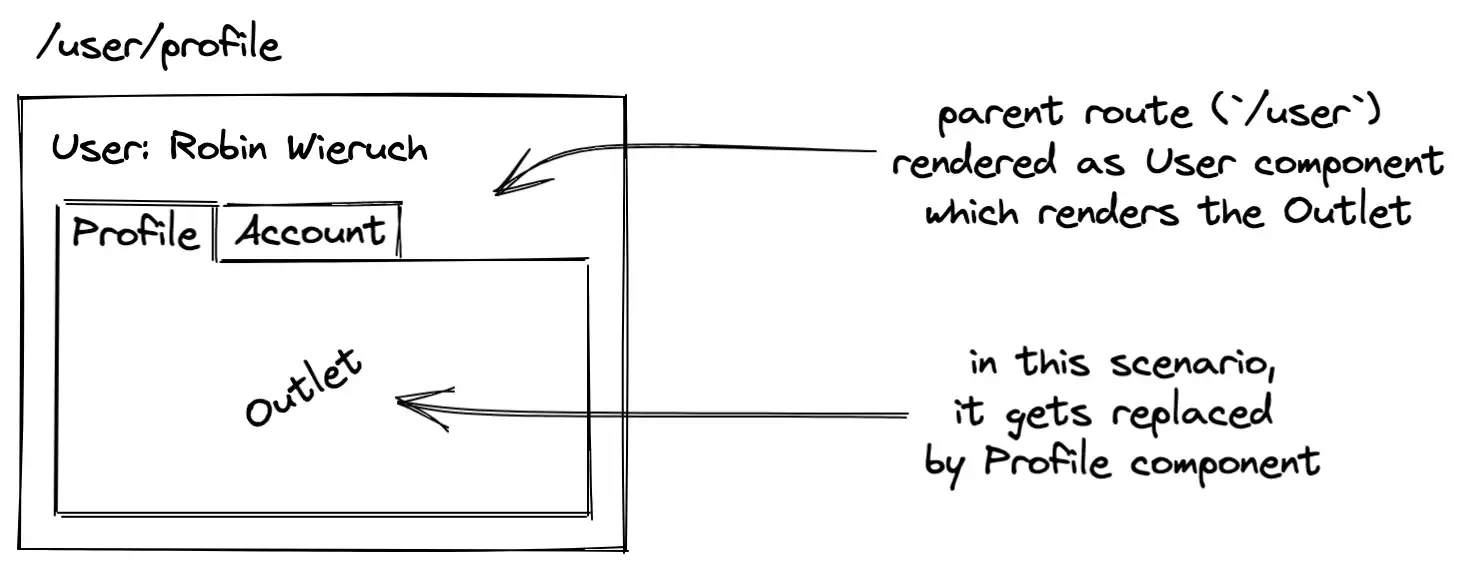 如果没有 /profile 和 /account 路由匹配(例如 /user/settings),你将只看到 User 组件出现。为避免这种情况,你可以添加索引和无匹配路由的组合。之后,默认路由将是 /profile 路由:
如果没有 /profile 和 /account 路由匹配(例如 /user/settings),你将只看到 User 组件出现。为避免这种情况,你可以添加索引和无匹配路由的组合。之后,默认路由将是 /profile 路由: